Early Development
Reussir turns memory reuse into a visible compiler system instead of a hidden runtime trick.
The project positions reuse at the IR level: explicit tokens, structured control flow, and backend-aware lowering passes inside MLIR. The result is a compiler story that is easier to inspect, easier to extend, and already competitive with Lean 4 while approaching Koka on several workloads.
Live system view
eliminate Pattern match
reuse resource token<A,S>
introduce Constructor rebuild
Thesis
What makes the project meaningful
Reussir is most compelling when it states the compiler argument directly: functional programs repeatedly destroy and rebuild values, and those introduction-elimination pairs are natural reuse sites.
IR-level framing
Reuse is modeled directly in the compiler IR
Reussir frames memory reuse as a first-class compilation problem. Instead of hiding optimization inside a language-specific calculus, it exposes reusable storage as explicit tokens inside MLIR.
Structured control flow
Tokens survive branches, joins, loops, and early returns
The analysis runs over SCF regions rather than only local match-construct pairs. That gives the pipeline a way to reason about reuse when the operational story spans multiple regions or call boundaries.
Backend consequences
Reuse decisions are tied to lowering quality, not just allocation counts
The implementation combines token reuse with RC creation sinking, RC-materialization fusion, simplified TRMc, and invariant-group propagation so the generated LLVM stays competitive.
Object Model
An interactive map of the RC reuse machinery
Click the nodes to inspect how ownership, borrowing, and reusable storage connect across the RC object model.
Compiler object model
Pipeline
The full backend pass graph
This shows the full backend pipeline rather than compressing it into a few narrative steps. It includes reuse-relevant passes, extra backend optimizations, generic MLIR lowering, and the LLVM cleanup stages.
Backend optimization pipeline
The current backend is intentionally broader than reuse analysis alone. Feature-support passes such as `Closure Outline`, `Region Patterns`, and `Compile PolyFFI` sit alongside reuse analysis and the later MLIR-to-LLVM lowering path.
Special Optimizations
Detailed expansions focus on the distinctive optimization work
Instead of inventing a stage-by-stage explainer, this section focuses on the distinctive optimizations: uniqueness-carrying recursion, RC sinking and fusion, invariant-group analysis, and simple TRMc.
Optimizations
Selected optimization
Interactive Story
Why reuse across call boundaries matters
The red-black tree result is the clearest demonstration. Toggle the scene to see the difference between local-only reuse and a token that can travel back to the caller.
Cross-call reuse lab
callee frame `rc.dec` releases a branch
Uniqueness creates a token, but it is stranded unless the pipeline threads it back out.
caller frame Constructor wants storage
The rebuild site is outside the recursive frame, so purely local reasoning misses the connection.
The token dies inside the recursive frame, so the caller reconstructs with a fresh allocation path.
Evidence
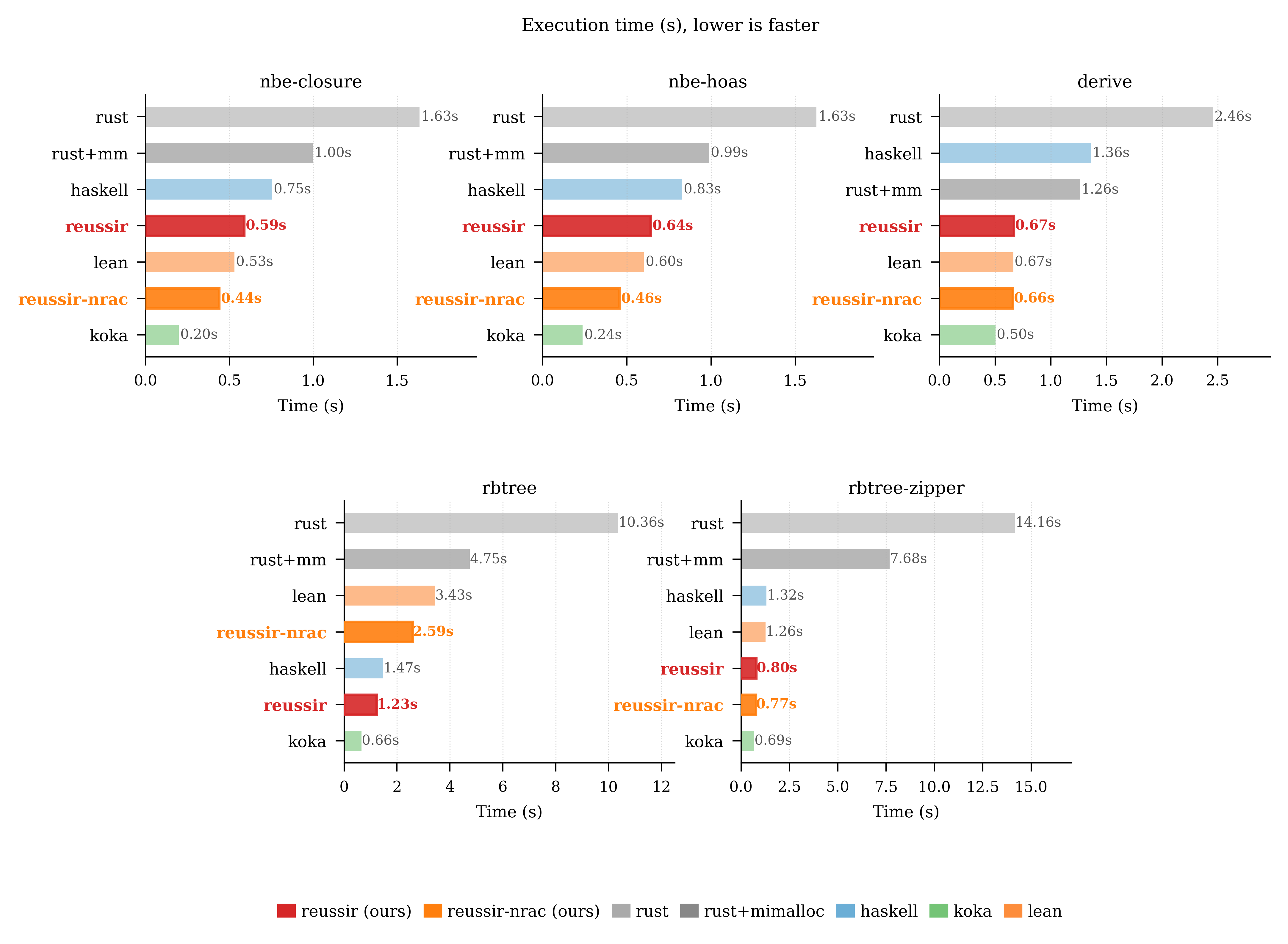
Benchmark results pulled into the page
The timing plot is included directly on the page, and the companion content summarizes the main performance takeaways instead of splitting the workloads into separate cards.
Paper figure
Current limitations
Koka still leads for understandable reasons
The remaining gaps are concrete: full TRMc, pointer tagging for nullary variants, and more compact variant layouts. That makes the gap actionable rather than vague.
Current Reussir runs from 517 MB to 777 MB across the measured workloads.
The largest memory gap comes from fixed-size variant padding and the lack of pointer tagging for fieldless variants.
On tree workloads, directly ported Rust code stays near 9 GB because persistence keeps intermediate structures alive.
Takeaway
A compiler framework, not just another RC language
Reussir makes reusable storage explicit, threads it through structured control flow, and measures the downstream codegen effects with real benchmarks.